
Arsenal
PingFang SC


TANKA • 03
在前篇中,我们暴力打通了所有数据管道。通常的工程师会告诉你:下一步该做 Index(索引)了。把数据切块、打标签、存进向量数据库。
但我告诉团队:停下。那是在制造“尸体”。
传统的索引(Index)和数据(Data)有一个致命的缺陷:它们没有主体(Subjectless)。
在传统数据库里,一条“销售记录”就是一条客观事实,它孤零零地躺在那里,不管是谁来读取,它都是那个样子。
但在 ANC(AI Native Company) 里,我们构建的是记忆(Memory)。记忆的本质区别在于:记忆必须依附于一个主体而存在。没有“主体”的参与,数据只是一堆混乱的字节。
同一个物理事实(比如“昨晚都在加班”):
对于项目经理(主体 A),这段记忆是“进度赶上了,团队士气高涨”。
对于新员工(主体 B),这段记忆是“流程混乱,不知道在忙什么”。
如果 Tanka 只是把“昨晚加班”这件事客观地索引下来,那它就是失真的。因为它丢失了最关键的维度——是谁在经历这件事?
所以,我们认为“索引化”不仅仅是给数据打标签,而是给数据寻找归属。我们不仅要记录“发生了什么”,还要记录“这对谁很重要”。
A 的记忆不能成为 B 的噪音。
正是因为记忆具有“主体性”,所以在 EverMemOS 的设计中,核心工程挑战不是“存储”,而是“隔离与提纯”。
“全量”是对系统而言的,“主观”是对个体而言的。
EverMind 是全知的,但作为个体的员工 A,绝不能直接借用员工 B 的大脑。这不仅是权限问题,更是认知逻辑问题。A 的主体经验如果是基于 B 的记忆构建的,那 A 就精神分裂了。
我们构建的不是一个平面的图书馆,而是一个多维的、以主体为中心的折叠宇宙。
系统必须能够回答:“基于主体 A 的视角,刚才那段对话意味着什么?”
当数据开始“呼吸”:EverMemOS 的技术实现
为了构建这个“以主体为中心的折叠宇宙”,我们必须从底层重构 AI 的认知架构。
一个真正的 AI-Native 公司,不仅要能捕捉数据,更要能让 AI 像人类一样拥有记忆;不是那种简单的、基于搜索的“外挂硬盘”,而是能够随时间演化、产生关联、支撑复杂决策的“数字大脑”。
于是,就有了 Tanka 核心的长期记忆系统:EverMemOS。
1. 我们在解决什么:为什么 Context 和传统的 RAG 无法承载 AI 原生企业的灵魂
当前的 AI 认知架构正处于从“工具属性”向“智能体属性”跨越的关键期。Manus 的出售,说明在 AI Agent 如火如荼的今天,依然还没能像上一代智能系统——搜索/推荐一样,基于数据飞轮构建深厚的用户体验壁垒。大模型的一次迭代,或者竞品的一次升级,都容易让先行者构建的壁垒失去优势。如何构建基于用户数据自我演进的 AI 系统,是 LLM 时代所有 AI 应用的目标。
在深入技术架构之前,必须先厘清记忆系统在 AI 原生 语境下到底要解决什么问题。
传统的 AI 应用在处理“记忆”时,比较常见会采用两种策略:一是将所有的上下文信息(Context)提供给 LLM,作为 LLM 的 Prompt 去处理;二是采用 RAG 架构,将检索结果提供给 LLM 去处理。无论是哪种方案,都面临着类脑科学中的“认知失调”挑战:
1.1 传统“无状态”架构的认知局限
在 AI-Native 的语境下,当前的 AI 应用若仅依赖 Context 和 RAG,本质上是在用“开卷考试”模拟“长期智力”。这种“无状态(Stateless)”的架构导致了以下深层次的缺陷:
1. 瞬时注意力的物理瓶颈:昂贵且低效的“内存”
传统方案试图通过盲目扩大上下文窗口(Context Window)来模拟记忆,但这仅相当于增加了瞬时的 RAM(类似人类的 Working Memory),而非持久的长期记忆。
成本与延迟的悖论:上下文的增加带来计算开销的指数级增长。当窗口溢出时,AI 会产生严重的“健忘症”与逻辑断裂,无法追踪跨度数月的项目演变。
信噪比的矛盾:随着背景信息的堆砌,由于注意力机制的局限,模型极易陷入“迷失中段(Lost in the Middle)”的困境,导致指令遵循能力和信息提取准确率大幅下降。
2. 检索与生成的深度割裂:缺乏主体的“碎片拼接”
现有的 RAG 架构本质上是“搜索+拼接”,它只是一个机械的搬运工,缺乏人类大脑中不同维度的记忆整合:
语义与情节的缺失:传统 RAG 无法区分语义记忆(事实与常识)与情节记忆(跨时间的事件序列),导致 AI 无法理解知识间的时序关系,只能给出缺乏逻辑深度的碎片化回复。
“人设”的失真:因为检索是“无主体”的,AI 无法根据用户的历史偏好和反馈进行深度个性化调整。它表现得像一个随机应变的翻译器,而非一个拥有连续行为逻辑、能够共同进化的专业合作伙伴。
3. 静态存储的演进死角:无法“巩固”的孤立数据
知识存入传统的向量数据库后便成为了互不相连的孤岛,缺乏类脑的动态处理能力:
缺乏记忆巩固(Consolidation):传统系统无法像人类一样,在交互间隙对信息进行抽象、压缩和关联更新。它不具备“反思”能力,无法通过多轮检索与推理挖掘隐含关系。
无法自我演化的壁垒:这种静态性导致先行者的优势极易被模型迭代所抹平。一个无法基于用户数据“自我进化”的系统,永远无法构建起真正的体验护城河,也无法承载 AI 原生 企业所需的“数字灵魂”。
1.2 记忆系统的仿生定义:从数据存储到主动演化
我们认为,长期记忆系统不应只是一个向量数据库,而应是一个动态演化的“认知操作系统”。这种理解源于对人类智力机制的模拟。
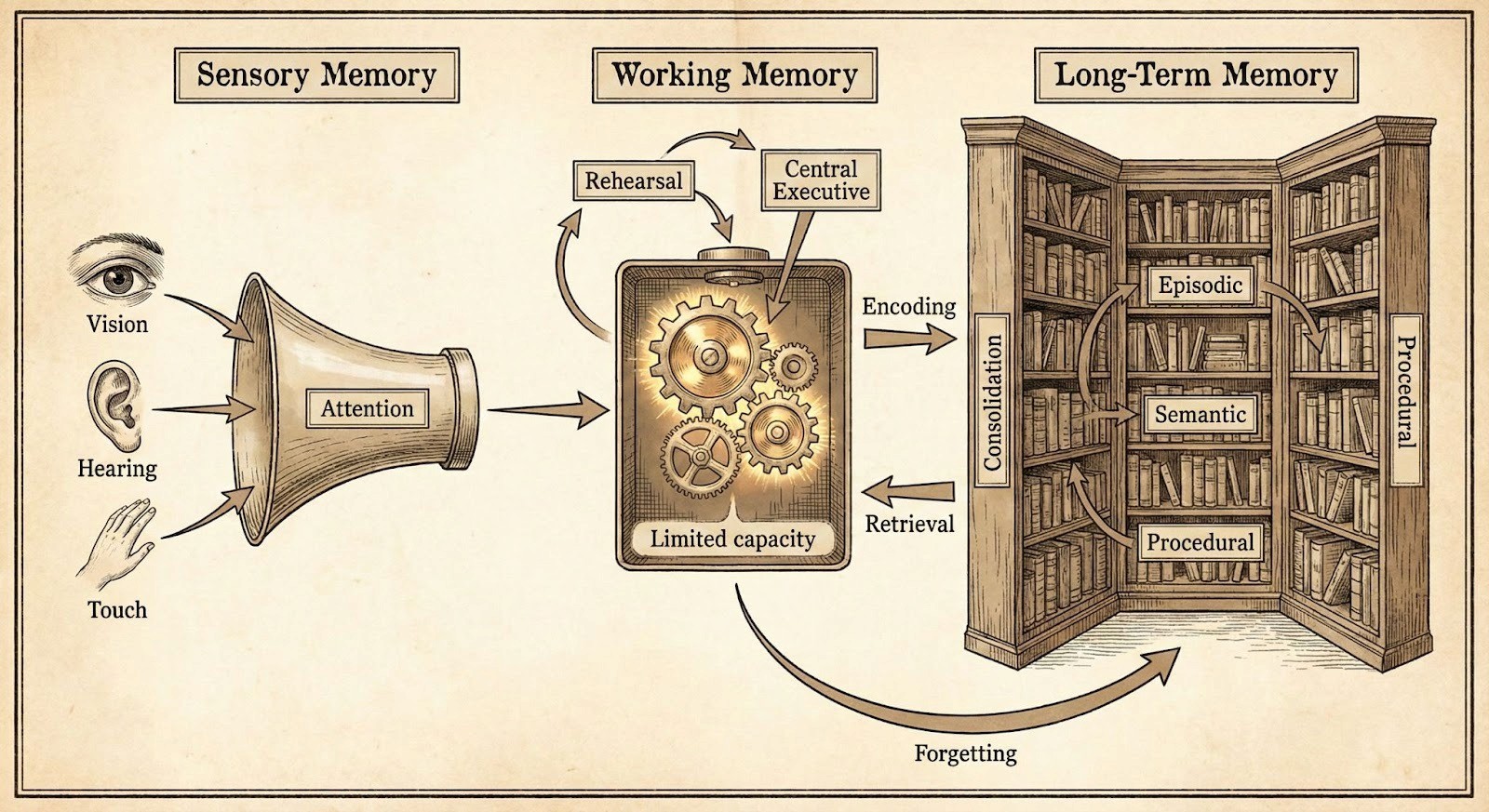
[图示:人类记忆系统示意图 - Sensory / Working / Long-Term Memory]
记忆维度 | 对应 AI 架构 | 核心功能与商业价值 |
工作记忆 (Working Memory) | LLM Context Window | 处理当前任务,保持信息活跃;一旦任务结束即释放空间。 |
情节记忆 (Episodic Memory) | 结构化对话日志 / Scenes | 记录具体的经历、故事与时间线;用于还原业务决策的因果链路。 |
语义记忆 (Semantic Memory) | 知识图谱 (KG) / 世界模型 | 存储事实、概念、规则与常识;形成企业的专有知识库与行业洞见。 |
程序记忆 (Procedural Memory) | 技能组件 / 操作流 (Action) | 存储技能与操作直觉;实现 AI 对复杂工作流的自动化执行。 |
长期记忆系统的核心使命,是实现从“Fluid Intelligence”(流体智力,基于即时推理)向“Crystallized Intelligence”(晶体智力,基于经验累积)的转化。它连接了时间与智能,使 AI 能够通过自我反馈进行持续演进,而非仅仅依赖预训练的静态权重。
在工程上,我们要解决的核心问题是:如何让 AI 拥有一个低成本、高效率,且具备自我演化能力的“长期记忆系统”。这个记忆系统要具有人类长期记忆的基本组件和功能,也要符合基于 LLM 的下一代 AI 系统的演化趋势。
2. Tanka 的已有实践:EverMemOS 1.0 的阶段性突破与实战检验
我们已经完成了记忆系统 EverMemOS 1.0 的核心架构设计,并成功将其作为认知基座应用于 Tanka 项目中,验证了长期记忆在企业级场景下的可行性。
2.1 EverMemOS 1.0 架构:层次化记忆组织
EverMemOS 1.0 采用了一种仿生学的记忆组织方式,将原始的对话流转化为可检索、可理解的知识结构。对于输入的原始数据,按照下述四个环节对数据进行记忆提取:
语义切分(Semantic Segmentation):不同于传统的固定 Token 切分,我们根据原始对话事件的语义边界进行划分,确保每一条记忆单元(MemCell)在语义上是闭合且低噪声的。
Episode 的双轨提取:系统为每一个记忆单元生成一个 Episode,并同时提取高精确度的“原子事实”(Atomic Facts)和隐含扩展的“远见”(ForeSight)的双轨信息。这种设计兼顾了表达的完整性和匹配的精确性。
记忆场景(Memory Scene):通过聚类算法将相似的 Episode 合并为 Scene,有效地抑制了检索时的冗余噪音,确保 AI 只在高相关的上下文中进行召回。此过程类似于人类长期记忆的巩固机制(Consolidation),将零散信息升华为结构化知识。
高层记忆建模(Profile Extraction):在基础记忆之上,系统对个体和群组进行深度画像(Profile)提取。包括涵盖身份信息、语言风格、特定偏好、专业技能及长期工作目标的个人画像;以及识别群内的意见领袖(KOL)、集体工作目标及成员特定角色的群组洞察。
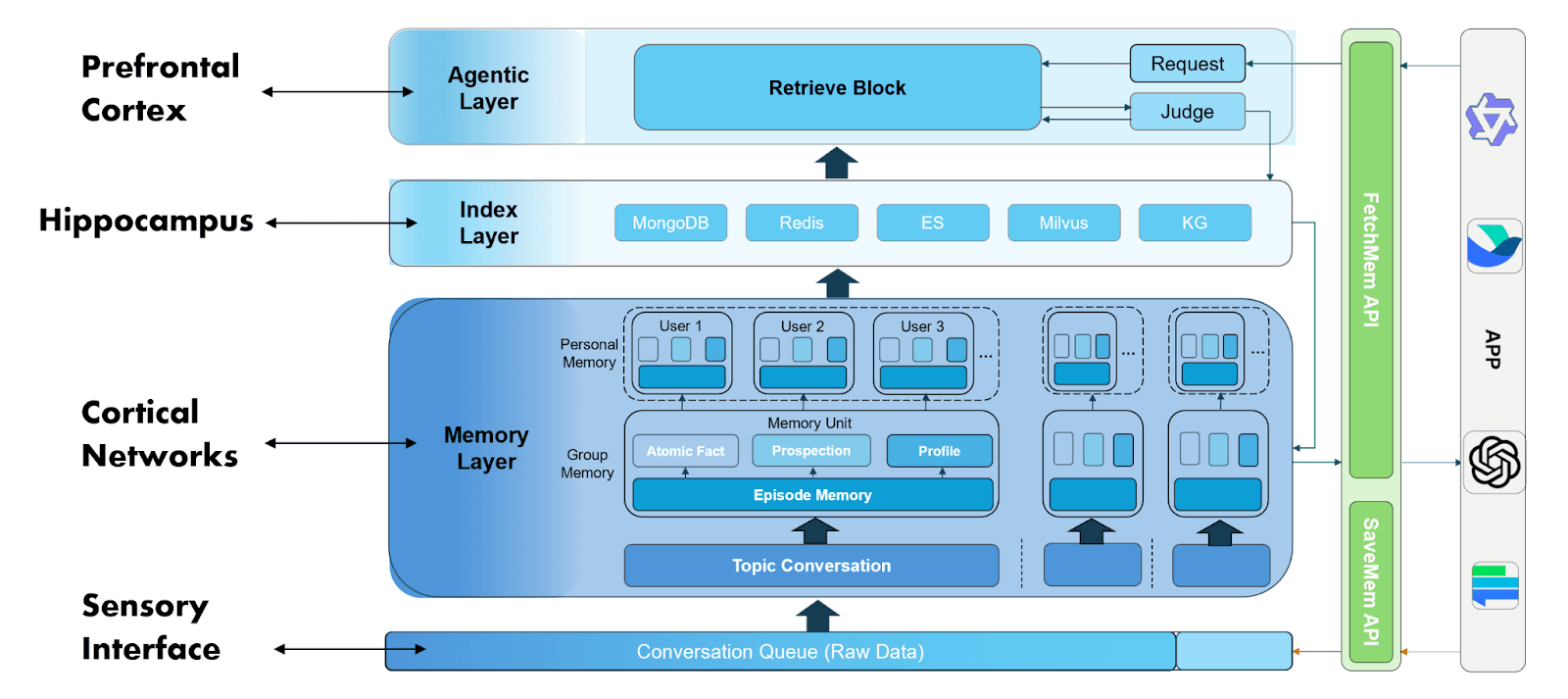
[图示:EverMemOS 1.0 系统架构图:从原始数据到高层 Profile 的演化路径]
在记忆使用阶段,则是使用类似前额叶皮层的 Agentic Layer 来完成记忆的使用。
2.2 性能评测
在行业主流的长期记忆 Benchmark 数据集 LoCoMo 上,EverMemOS 以较低的 Token 消耗取得了超越同期竞品的准确率。
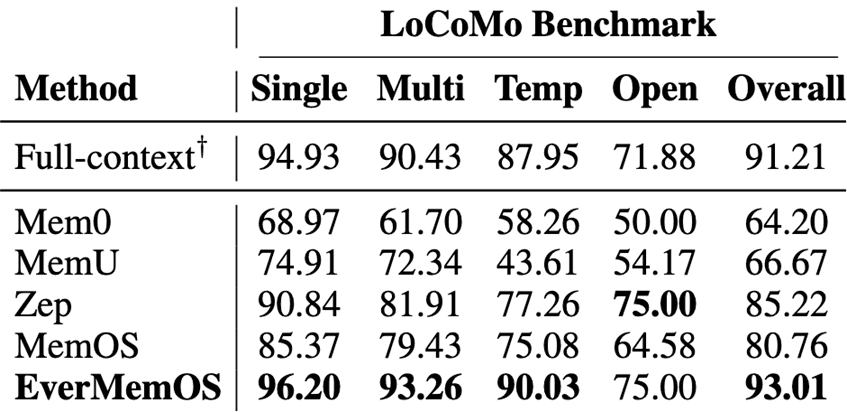
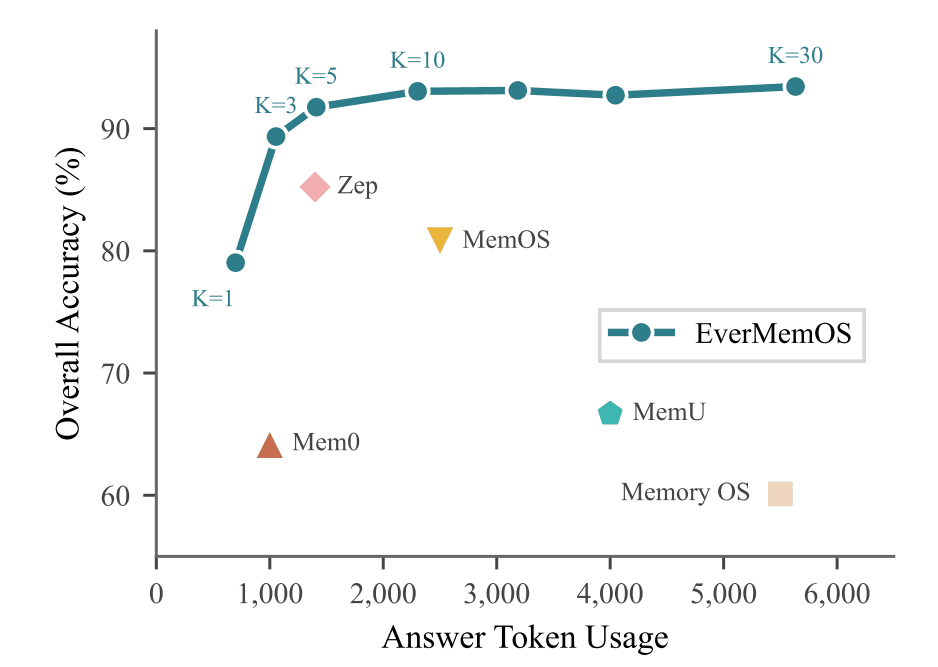
[图示:LoCoMo Benchmark 评测效果:展示 EverMemOS 的高精度与低能耗表现]
实验数据证明,EverMemOS 是目前唯一一个在多项指标上超过“LLM Full Context”模式的记忆系统,且其平均占用的 Token 数仅为后者的十分之一。此外,在 LongMemEval、PersonaMem 和 HaluMem 等长期记忆基准测试中,EverMemOS 均达到了 SOTA(State-of-the-Art) 水平。
2.3 产品价值:Tanka 企业协作平台的“认知中枢”
EverMemOS 1.0 已经在 Tanka 实际部署,通过 Tanka Link 接入 Chat、Memo、Email、Google Doc、Notion 等不同数据格式的数据源,并进行长期记忆提取。
截止 2025 年 12 月,该系统已处理了近千万条跨越邮件、文档和即时聊天的数据。Tanka 的诸多 AI 功能,如 Assistant、Work、People 等通过 EverMemOS 维护的共同记忆,提升了用户体验。AI 不再只是根据当前对话回复,而是能够结合几个月前的会议摘要和用户的隐含偏好进行决策支持。
随着记忆系统的使用,特别是对接业务系统的各种需求,我们发现 EverMemOS 1.0 虽然在同阶段的记忆系统中处于领先地位,但是依然存在下述挑战:
如何做好记忆管理:需要更好地支持记忆的删除、隐私保护、记忆的继承等记忆管理功能;
如何做好不同应用的适配:记忆系统的语义分割和基础记忆的提取是通用的,但 Profile 等高层信息往往是与应用场景相关的。以个人的技能举例,已有的记忆系统往往会提前定义 90 类或者 120 类技能集合,并利用 LLM 进行提取。但挑战在于,为什么是 90 种,或 120 种?而且不同的行业、场景,或者公司,对技能的偏好是不同的。
如何做到基于用户反馈更新:虽然今天的记忆系统,已经具有一定的自适应能力,但距离人们期待的像人类记忆系统或者 AI 推荐系统一样,能够基于人类和 AI 的交互自我演进尚有距离。
3. 迈向未来:构建具备“思考能力”与“数据飞轮”的 Agentic 记忆系统
未来的记忆系统不应只是简单的“数据存档”,而应是具备“思考能力”的 Agentic 系统;不应只是静态提取的工作流工具,而应是一个能够形成用户数据飞轮的动态演化系统。面对上述挑战,我们将从以下几个维度进行深度探索与重构:
3.1 兼顾安全与灵活的底层记忆管理
针对记忆删除与隐私保护等基础功能的挑战,我们致力于在底层架构中植入更细粒度的控制机制:
多维隐私标签体系:在记忆提取阶段,系统将自动为生成的每一条 MemCell (记忆单元)标记隐私属性。这种内生的标签体系使得应用侧可以根据特定场景(如 Arena 竞技或企业内部合规)一键开启隐私过滤开关,确保敏感信息在处理链路中的绝对安全。
记忆继承与生命周期管理:建立标准化的存储与持久化接口,确保记忆能够跨越不同 AI 会话与系统版本进行延续,真正实现 AI 的“数字遗产”式管理。
3.2 场景自适应的分布式 Profile 架构
为了解决不同应用、组织对 Profile (画像)定义的偏好差异,我们摒弃了“预设固定技能集”的僵化思路,转向更具弹性的配置化方案:
可插拔式 Profile 配置:系统在提取默认画像信息的同时,支持应用侧通过独立的配置文件自定义画像维度。这使得记忆系统既能通用化部署,也能快速适配特定行业或公司的专属技能模型。
偏好强化学习(RL-based Preference):在 Memory Utilization 层,我们通过强化学习(RL)技术直接从交互证据(Evidence)中提取用户的潜在偏好。这种方案无需大幅修改底层逻辑,即可让模型在无须显式定义的情况下,自发地向用户或行业的独特性格靠拢。
3.3 构建基于交互反馈的自我演进飞轮
实现记忆系统像推荐系统一样自我进化的关键,在于从“单向管道”向“循环迭代”模式的转变:
强化学习驱动的动态优化:我们会构建基于强化学习的记忆系统,将传统的 Pipeline 模式进化为 RL Iteration 模式。通过将 QA 准确率、记忆幻觉率等指标作为 Reward (奖励)信号,训练系统在“记忆切分-提取-使用”的全链条中进行自我对齐与优化。
工程化的反馈闭环:在实现完全的持续学习之前,我们通过工程手段先行支持用户反馈更新。系统将自动提取对话中的高价值数据(如明确的喜好、后续反馈 follow-up 等),并以此作为类似于“注意力机制(Attention)”的权重,实时影响 AI 的后续响应行为。
通过上述探索,我们期望 EverMemOS 能够真正打破“静态数据孤岛”的局限,演化为一个具有长期一致性、深度个性化且能够伴随用户共同成长的“数字大脑”。
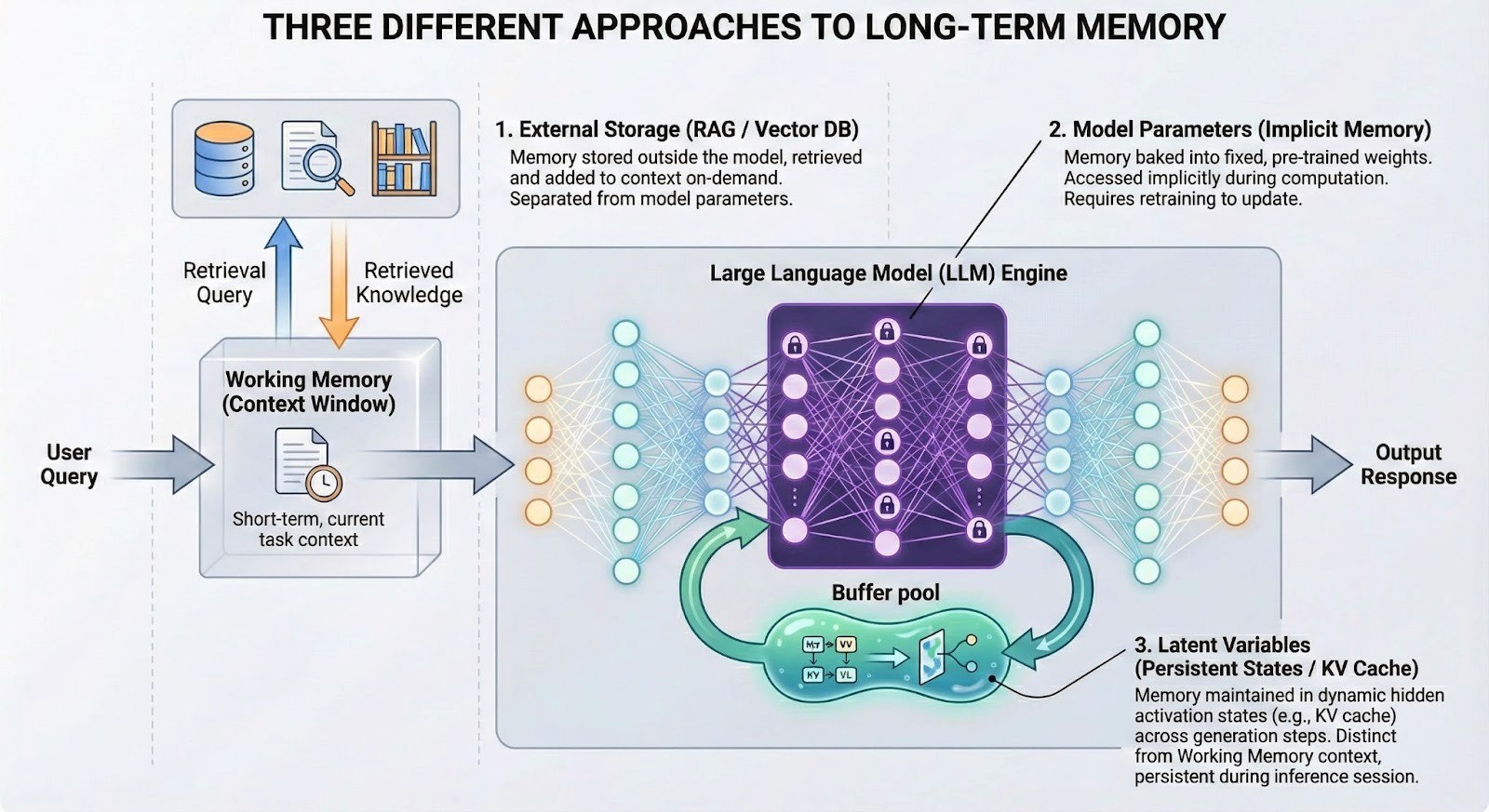
[图示:AI 长期记忆系统三种路径复合架构图 (External Storage / Model Parameters / Latent Variables)]
除此之外,为了更好地推进系统演进,我们还将构建下一代记忆系统的评测准则——EverMemBench。在评测准则上,我们致力于推动长期记忆系统从“初级检索”向“高级认知”跨越,目标是构建能够作为用户“第二自我 (Alter Ego)”的智能体系。我们将通过以下三个维度重新定义评测标准:
三轨并行架构:建立包含 300M Token 级的超大规模压力测试(Track 1)、模拟真实世界信息迭代的 1 对 1 动态更新测试(Track 2),以及考察多主题交叉与跨群组人设迁移的复杂群组动力学测试(Track 3)。
深化记忆感知:评测不仅关注系统“是否记住事实”,更强调系统能否在恰当时机识别当前任务与历史信息的隐性因果关联(如术后恢复对聚餐建议的影响),使记忆真正影响当前决策。
强化用户画像理解:考察系统能否维持连贯的“风格一致性”与“决策一致性”,确保 AI 在代写、谈判等复杂交互中体现用户稳定的个性特征、风险偏好与价值取向,拒绝平庸且矛盾的行为模式。
4. 差异化优势:未来的 Tanka 将呈现什么?
在 EverMemOS 的深度赋能下,未来的 Tanka 将彻底超越传统办公协作工具的范畴。它不再仅仅是一个任务处理工具,而是一个具备进化能力的“数字大脑”,通过以下四个核心维度重塑 AI 原生 企业的生产力壁垒:
4.1 极致的上下文意识:消灭信息重复
Tanka 拥有跨越 Session 限制的“长程记忆”。
历史回溯:它不仅记得当前对话,还记得三个月前某个方案被否决的底层逻辑。
深度背景感知:用户无需重复背景信息,AI 能够自动关联过往的项目细节与合作伙伴的特定偏好。
4.2 “人设守恒”下的行为一致性:AI 的人格化跨越
基于长期记忆,Tanka 的 AI 助手 能够从海量交互中归纳出用户的隐式偏好。
风格自适应:系统能感知经理对“成本控制”和“正式态度”的重视。当起草通知时,AI 会自动采用正式文书风格,并在预算环节主动设置警戒线。
拒绝无状态平庸:这种基于历史反馈的深度个性化,确保了 AI 行为的连续性,使其从“随机应变的翻译器”进化为“专业且懂你的合作伙伴”。
4.3 “个性化偏见”:拒绝平庸的完美
我们坚信,AI 的价值不应体现在产出趋同的完美模板,而应体现在对用户思维框架的承接。
灵魂注入:通过注入用户的独特偏见与视角,Tanka 产出的每一份文档都将带有用户专属的逻辑灵魂。
价值增值:这种“不完美但有价值”的产出,才是 AI 原生 企业对抗低效平庸、实现差异化竞争的关键。
4.4 组织资产的永续增值:对抗人才流失的认知防火墙
传统企业面临最大的挑战是关键员工离职带来的“认知流失”。
经验沉淀:Tanka 通过全量管道捕捉业务现实的每一个比特,将那些“非正式流程”和“客户洞察”沉淀为企业的长期记忆。
认知跃迁:这种资产化的记忆使系统实现从“响应式”到“预测式”的飞跃。即使团队成员更迭,企业的“数字大脑”依然能够基于积累的认知资产持续进化。
结语:进化始于记忆
在 AI 原生 公司的开源日志中,我们正逐步推进:从打破隐私的执念(Data vs. Privacy),到接入每一比特的业务真实(Data Piping),再到如今重构 AI 的认知中枢(Memory System)。
长期记忆系统的建立,标志着 AI 终于从“瞬时计算的机器”变成了“具备时间感的智能体”。在 Tanka 的生态中,记忆不再是历史的负担,而是进化的动力。
通过 EverMemOS 的仿生架构与 RL 优化策略,我们正在构建一个能够记住过去、理解当下、并预测未来的认知底座。因为在 AI 时代的竞争中,最终胜出的将不是算力最强的公司,而是那些能够最深刻地沉淀并利用“经验”的公司。
我们拒绝平庸的效率,我们追求的是让每一比特的业务现实,都能在 AI 的大脑中产生回响。
在前篇中,我们暴力打通了所有数据管道。通常的工程师会告诉你:下一步该做 Index(索引)了。把数据切块、打标签、存进向量数据库。
但我告诉团队:停下。那是在制造“尸体”。
传统的索引(Index)和数据(Data)有一个致命的缺陷:它们没有主体(Subjectless)。
在传统数据库里,一条“销售记录”就是一条客观事实,它孤零零地躺在那里,不管是谁来读取,它都是那个样子。
但在 ANC(AI Native Company) 里,我们构建的是记忆(Memory)。记忆的本质区别在于:记忆必须依附于一个主体而存在。没有“主体”的参与,数据只是一堆混乱的字节。
同一个物理事实(比如“昨晚都在加班”):
对于项目经理(主体 A),这段记忆是“进度赶上了,团队士气高涨”。
对于新员工(主体 B),这段记忆是“流程混乱,不知道在忙什么”。
如果 Tanka 只是把“昨晚加班”这件事客观地索引下来,那它就是失真的。因为它丢失了最关键的维度——是谁在经历这件事?
所以,我们认为“索引化”不仅仅是给数据打标签,而是给数据寻找归属。我们不仅要记录“发生了什么”,还要记录“这对谁很重要”。
A 的记忆不能成为 B 的噪音。
正是因为记忆具有“主体性”,所以在 EverMemOS 的设计中,核心工程挑战不是“存储”,而是“隔离与提纯”。
“全量”是对系统而言的,“主观”是对个体而言的。
EverMind 是全知的,但作为个体的员工 A,绝不能直接借用员工 B 的大脑。这不仅是权限问题,更是认知逻辑问题。A 的主体经验如果是基于 B 的记忆构建的,那 A 就精神分裂了。
我们构建的不是一个平面的图书馆,而是一个多维的、以主体为中心的折叠宇宙。
系统必须能够回答:“基于主体 A 的视角,刚才那段对话意味着什么?”
当数据开始“呼吸”:EverMemOS 的技术实现
为了构建这个“以主体为中心的折叠宇宙”,我们必须从底层重构 AI 的认知架构。
一个真正的 AI-Native 公司,不仅要能捕捉数据,更要能让 AI 像人类一样拥有记忆;不是那种简单的、基于搜索的“外挂硬盘”,而是能够随时间演化、产生关联、支撑复杂决策的“数字大脑”。
于是,就有了 Tanka 核心的长期记忆系统:EverMemOS。
1. 我们在解决什么:为什么 Context 和传统的 RAG 无法承载 AI 原生企业的灵魂
当前的 AI 认知架构正处于从“工具属性”向“智能体属性”跨越的关键期。Manus 的出售,说明在 AI Agent 如火如荼的今天,依然还没能像上一代智能系统——搜索/推荐一样,基于数据飞轮构建深厚的用户体验壁垒。大模型的一次迭代,或者竞品的一次升级,都容易让先行者构建的壁垒失去优势。如何构建基于用户数据自我演进的 AI 系统,是 LLM 时代所有 AI 应用的目标。
在深入技术架构之前,必须先厘清记忆系统在 AI 原生 语境下到底要解决什么问题。
传统的 AI 应用在处理“记忆”时,比较常见会采用两种策略:一是将所有的上下文信息(Context)提供给 LLM,作为 LLM 的 Prompt 去处理;二是采用 RAG 架构,将检索结果提供给 LLM 去处理。无论是哪种方案,都面临着类脑科学中的“认知失调”挑战:
1.1 传统“无状态”架构的认知局限
在 AI-Native 的语境下,当前的 AI 应用若仅依赖 Context 和 RAG,本质上是在用“开卷考试”模拟“长期智力”。这种“无状态(Stateless)”的架构导致了以下深层次的缺陷:
1. 瞬时注意力的物理瓶颈:昂贵且低效的“内存”
传统方案试图通过盲目扩大上下文窗口(Context Window)来模拟记忆,但这仅相当于增加了瞬时的 RAM(类似人类的 Working Memory),而非持久的长期记忆。
成本与延迟的悖论:上下文的增加带来计算开销的指数级增长。当窗口溢出时,AI 会产生严重的“健忘症”与逻辑断裂,无法追踪跨度数月的项目演变。
信噪比的矛盾:随着背景信息的堆砌,由于注意力机制的局限,模型极易陷入“迷失中段(Lost in the Middle)”的困境,导致指令遵循能力和信息提取准确率大幅下降。
2. 检索与生成的深度割裂:缺乏主体的“碎片拼接”
现有的 RAG 架构本质上是“搜索+拼接”,它只是一个机械的搬运工,缺乏人类大脑中不同维度的记忆整合:
语义与情节的缺失:传统 RAG 无法区分语义记忆(事实与常识)与情节记忆(跨时间的事件序列),导致 AI 无法理解知识间的时序关系,只能给出缺乏逻辑深度的碎片化回复。
“人设”的失真:因为检索是“无主体”的,AI 无法根据用户的历史偏好和反馈进行深度个性化调整。它表现得像一个随机应变的翻译器,而非一个拥有连续行为逻辑、能够共同进化的专业合作伙伴。
3. 静态存储的演进死角:无法“巩固”的孤立数据
知识存入传统的向量数据库后便成为了互不相连的孤岛,缺乏类脑的动态处理能力:
缺乏记忆巩固(Consolidation):传统系统无法像人类一样,在交互间隙对信息进行抽象、压缩和关联更新。它不具备“反思”能力,无法通过多轮检索与推理挖掘隐含关系。
无法自我演化的壁垒:这种静态性导致先行者的优势极易被模型迭代所抹平。一个无法基于用户数据“自我进化”的系统,永远无法构建起真正的体验护城河,也无法承载 AI 原生 企业所需的“数字灵魂”。
1.2 记忆系统的仿生定义:从数据存储到主动演化
我们认为,长期记忆系统不应只是一个向量数据库,而应是一个动态演化的“认知操作系统”。这种理解源于对人类智力机制的模拟。
[图示:人类记忆系统示意图 - Sensory / Working / Long-Term Memory]
记忆维度 | 对应 AI 架构 | 核心功能与商业价值 |
工作记忆 (Working Memory) | LLM Context Window | 处理当前任务,保持信息活跃;一旦任务结束即释放空间。 |
情节记忆 (Episodic Memory) | 结构化对话日志 / Scenes | 记录具体的经历、故事与时间线;用于还原业务决策的因果链路。 |
语义记忆 (Semantic Memory) | 知识图谱 (KG) / 世界模型 | 存储事实、概念、规则与常识;形成企业的专有知识库与行业洞见。 |
程序记忆 (Procedural Memory) | 技能组件 / 操作流 (Action) | 存储技能与操作直觉;实现 AI 对复杂工作流的自动化执行。 |
长期记忆系统的核心使命,是实现从“Fluid Intelligence”(流体智力,基于即时推理)向“Crystallized Intelligence”(晶体智力,基于经验累积)的转化。它连接了时间与智能,使 AI 能够通过自我反馈进行持续演进,而非仅仅依赖预训练的静态权重。
在工程上,我们要解决的核心问题是:如何让 AI 拥有一个低成本、高效率,且具备自我演化能力的“长期记忆系统”。这个记忆系统要具有人类长期记忆的基本组件和功能,也要符合基于 LLM 的下一代 AI 系统的演化趋势。
2. Tanka 的已有实践:EverMemOS 1.0 的阶段性突破与实战检验
我们已经完成了记忆系统 EverMemOS 1.0 的核心架构设计,并成功将其作为认知基座应用于 Tanka 项目中,验证了长期记忆在企业级场景下的可行性。
2.1 EverMemOS 1.0 架构:层次化记忆组织
EverMemOS 1.0 采用了一种仿生学的记忆组织方式,将原始的对话流转化为可检索、可理解的知识结构。对于输入的原始数据,按照下述四个环节对数据进行记忆提取:
语义切分(Semantic Segmentation):不同于传统的固定 Token 切分,我们根据原始对话事件的语义边界进行划分,确保每一条记忆单元(MemCell)在语义上是闭合且低噪声的。
Episode 的双轨提取:系统为每一个记忆单元生成一个 Episode,并同时提取高精确度的“原子事实”(Atomic Facts)和隐含扩展的“远见”(ForeSight)的双轨信息。这种设计兼顾了表达的完整性和匹配的精确性。
记忆场景(Memory Scene):通过聚类算法将相似的 Episode 合并为 Scene,有效地抑制了检索时的冗余噪音,确保 AI 只在高相关的上下文中进行召回。此过程类似于人类长期记忆的巩固机制(Consolidation),将零散信息升华为结构化知识。
高层记忆建模(Profile Extraction):在基础记忆之上,系统对个体和群组进行深度画像(Profile)提取。包括涵盖身份信息、语言风格、特定偏好、专业技能及长期工作目标的个人画像;以及识别群内的意见领袖(KOL)、集体工作目标及成员特定角色的群组洞察。
[图示:EverMemOS 1.0 系统架构图:从原始数据到高层 Profile 的演化路径]
在记忆使用阶段,则是使用类似前额叶皮层的 Agentic Layer 来完成记忆的使用。
2.2 性能评测
在行业主流的长期记忆 Benchmark 数据集 LoCoMo 上,EverMemOS 以较低的 Token 消耗取得了超越同期竞品的准确率。
[图示:LoCoMo Benchmark 评测效果:展示 EverMemOS 的高精度与低能耗表现]
实验数据证明,EverMemOS 是目前唯一一个在多项指标上超过“LLM Full Context”模式的记忆系统,且其平均占用的 Token 数仅为后者的十分之一。此外,在 LongMemEval、PersonaMem 和 HaluMem 等长期记忆基准测试中,EverMemOS 均达到了 SOTA(State-of-the-Art) 水平。
2.3 产品价值:Tanka 企业协作平台的“认知中枢”
EverMemOS 1.0 已经在 Tanka 实际部署,通过 Tanka Link 接入 Chat、Memo、Email、Google Doc、Notion 等不同数据格式的数据源,并进行长期记忆提取。
截止 2025 年 12 月,该系统已处理了近千万条跨越邮件、文档和即时聊天的数据。Tanka 的诸多 AI 功能,如 Assistant、Work、People 等通过 EverMemOS 维护的共同记忆,提升了用户体验。AI 不再只是根据当前对话回复,而是能够结合几个月前的会议摘要和用户的隐含偏好进行决策支持。
随着记忆系统的使用,特别是对接业务系统的各种需求,我们发现 EverMemOS 1.0 虽然在同阶段的记忆系统中处于领先地位,但是依然存在下述挑战:
如何做好记忆管理:需要更好地支持记忆的删除、隐私保护、记忆的继承等记忆管理功能;
如何做好不同应用的适配:记忆系统的语义分割和基础记忆的提取是通用的,但 Profile 等高层信息往往是与应用场景相关的。以个人的技能举例,已有的记忆系统往往会提前定义 90 类或者 120 类技能集合,并利用 LLM 进行提取。但挑战在于,为什么是 90 种,或 120 种?而且不同的行业、场景,或者公司,对技能的偏好是不同的。
如何做到基于用户反馈更新:虽然今天的记忆系统,已经具有一定的自适应能力,但距离人们期待的像人类记忆系统或者 AI 推荐系统一样,能够基于人类和 AI 的交互自我演进尚有距离。
3. 迈向未来:构建具备“思考能力”与“数据飞轮”的 Agentic 记忆系统
未来的记忆系统不应只是简单的“数据存档”,而应是具备“思考能力”的 Agentic 系统;不应只是静态提取的工作流工具,而应是一个能够形成用户数据飞轮的动态演化系统。面对上述挑战,我们将从以下几个维度进行深度探索与重构:
3.1 兼顾安全与灵活的底层记忆管理
针对记忆删除与隐私保护等基础功能的挑战,我们致力于在底层架构中植入更细粒度的控制机制:
多维隐私标签体系:在记忆提取阶段,系统将自动为生成的每一条 MemCell (记忆单元)标记隐私属性。这种内生的标签体系使得应用侧可以根据特定场景(如 Arena 竞技或企业内部合规)一键开启隐私过滤开关,确保敏感信息在处理链路中的绝对安全。
记忆继承与生命周期管理:建立标准化的存储与持久化接口,确保记忆能够跨越不同 AI 会话与系统版本进行延续,真正实现 AI 的“数字遗产”式管理。
3.2 场景自适应的分布式 Profile 架构
为了解决不同应用、组织对 Profile (画像)定义的偏好差异,我们摒弃了“预设固定技能集”的僵化思路,转向更具弹性的配置化方案:
可插拔式 Profile 配置:系统在提取默认画像信息的同时,支持应用侧通过独立的配置文件自定义画像维度。这使得记忆系统既能通用化部署,也能快速适配特定行业或公司的专属技能模型。
偏好强化学习(RL-based Preference):在 Memory Utilization 层,我们通过强化学习(RL)技术直接从交互证据(Evidence)中提取用户的潜在偏好。这种方案无需大幅修改底层逻辑,即可让模型在无须显式定义的情况下,自发地向用户或行业的独特性格靠拢。
3.3 构建基于交互反馈的自我演进飞轮
实现记忆系统像推荐系统一样自我进化的关键,在于从“单向管道”向“循环迭代”模式的转变:
强化学习驱动的动态优化:我们会构建基于强化学习的记忆系统,将传统的 Pipeline 模式进化为 RL Iteration 模式。通过将 QA 准确率、记忆幻觉率等指标作为 Reward (奖励)信号,训练系统在“记忆切分-提取-使用”的全链条中进行自我对齐与优化。
工程化的反馈闭环:在实现完全的持续学习之前,我们通过工程手段先行支持用户反馈更新。系统将自动提取对话中的高价值数据(如明确的喜好、后续反馈 follow-up 等),并以此作为类似于“注意力机制(Attention)”的权重,实时影响 AI 的后续响应行为。
通过上述探索,我们期望 EverMemOS 能够真正打破“静态数据孤岛”的局限,演化为一个具有长期一致性、深度个性化且能够伴随用户共同成长的“数字大脑”。
[图示:AI 长期记忆系统三种路径复合架构图 (External Storage / Model Parameters / Latent Variables)]
除此之外,为了更好地推进系统演进,我们还将构建下一代记忆系统的评测准则——EverMemBench。在评测准则上,我们致力于推动长期记忆系统从“初级检索”向“高级认知”跨越,目标是构建能够作为用户“第二自我 (Alter Ego)”的智能体系。我们将通过以下三个维度重新定义评测标准:
三轨并行架构:建立包含 300M Token 级的超大规模压力测试(Track 1)、模拟真实世界信息迭代的 1 对 1 动态更新测试(Track 2),以及考察多主题交叉与跨群组人设迁移的复杂群组动力学测试(Track 3)。
深化记忆感知:评测不仅关注系统“是否记住事实”,更强调系统能否在恰当时机识别当前任务与历史信息的隐性因果关联(如术后恢复对聚餐建议的影响),使记忆真正影响当前决策。
强化用户画像理解:考察系统能否维持连贯的“风格一致性”与“决策一致性”,确保 AI 在代写、谈判等复杂交互中体现用户稳定的个性特征、风险偏好与价值取向,拒绝平庸且矛盾的行为模式。
4. 差异化优势:未来的 Tanka 将呈现什么?
在 EverMemOS 的深度赋能下,未来的 Tanka 将彻底超越传统办公协作工具的范畴。它不再仅仅是一个任务处理工具,而是一个具备进化能力的“数字大脑”,通过以下四个核心维度重塑 AI 原生 企业的生产力壁垒:
4.1 极致的上下文意识:消灭信息重复
Tanka 拥有跨越 Session 限制的“长程记忆”。
历史回溯:它不仅记得当前对话,还记得三个月前某个方案被否决的底层逻辑。
深度背景感知:用户无需重复背景信息,AI 能够自动关联过往的项目细节与合作伙伴的特定偏好。
4.2 “人设守恒”下的行为一致性:AI 的人格化跨越
基于长期记忆,Tanka 的 AI 助手 能够从海量交互中归纳出用户的隐式偏好。
风格自适应:系统能感知经理对“成本控制”和“正式态度”的重视。当起草通知时,AI 会自动采用正式文书风格,并在预算环节主动设置警戒线。
拒绝无状态平庸:这种基于历史反馈的深度个性化,确保了 AI 行为的连续性,使其从“随机应变的翻译器”进化为“专业且懂你的合作伙伴”。
4.3 “个性化偏见”:拒绝平庸的完美
我们坚信,AI 的价值不应体现在产出趋同的完美模板,而应体现在对用户思维框架的承接。
灵魂注入:通过注入用户的独特偏见与视角,Tanka 产出的每一份文档都将带有用户专属的逻辑灵魂。
价值增值:这种“不完美但有价值”的产出,才是 AI 原生 企业对抗低效平庸、实现差异化竞争的关键。
4.4 组织资产的永续增值:对抗人才流失的认知防火墙
传统企业面临最大的挑战是关键员工离职带来的“认知流失”。
经验沉淀:Tanka 通过全量管道捕捉业务现实的每一个比特,将那些“非正式流程”和“客户洞察”沉淀为企业的长期记忆。
认知跃迁:这种资产化的记忆使系统实现从“响应式”到“预测式”的飞跃。即使团队成员更迭,企业的“数字大脑”依然能够基于积累的认知资产持续进化。
结语:进化始于记忆
在 AI 原生 公司的开源日志中,我们正逐步推进:从打破隐私的执念(Data vs. Privacy),到接入每一比特的业务真实(Data Piping),再到如今重构 AI 的认知中枢(Memory System)。
长期记忆系统的建立,标志着 AI 终于从“瞬时计算的机器”变成了“具备时间感的智能体”。在 Tanka 的生态中,记忆不再是历史的负担,而是进化的动力。
通过 EverMemOS 的仿生架构与 RL 优化策略,我们正在构建一个能够记住过去、理解当下、并预测未来的认知底座。因为在 AI 时代的竞争中,最终胜出的将不是算力最强的公司,而是那些能够最深刻地沉淀并利用“经验”的公司。
我们拒绝平庸的效率,我们追求的是让每一比特的业务现实,都能在 AI 的大脑中产生回响。

作者 邓亚峰
VP of Shanda Group & CEO of EverMind
邓亚峰,盛大集团副总裁、EverMind CEO。 毕业于清华大学,拥有逾 20 年 AI 算法与产品研发底蕴。他正率领团队通过构建世界级的开源记忆操作系统,定义下一代 AI 基础设施,旨在将无状态 AI 转化为具备记忆、学习与进化能力的智能体。邓亚峰荣膺“2021 中国 AI 年度十大风云人物”,其领导的团队多次在国际顶级 AI 评测中斩获佳绩。作为资深研究者,他持有 160 余项发明专利,并在《Nature》子刊等学术期刊发表论文 50 余篇。


