
Arsenal
PingFang SC
全量管道 (Data Piping) —— 接入每一比特的业务真实


1. 从一张表格开始的“绝望计算”

故事的起点是一份被丢进 Slack 群的《公司付费软件统计表》。Notion, Slack, Zoom, Linear, Figma, Midjourney, Cursor... 统计显示,我们正在为 86 个不同的 SaaS 工具付费。
在 Tanka 的愿景里,我们需要通过 Tanka Link(这是我们连接外部世界的全量数据触手) 建立一条全量管道(Data Piping),把这些散落在各个孤岛中的数据接入 Tanka Memory。
一开始,研发团队的反应是线性的:“既然有 86 个,那我们就列个优先级,调研一批,排期一批,一个一个接。”
但紧接着,内部讨论推翻了这个逻辑。对于 Memory(记忆)而言,它不是一个“做减法”的选择题,而是一个“全量”的命题。因为你永远不知道哪一比特的碎片信息,会在未来成为 AI 决策的关键上下文。
所以,我们的目标不是“选几个好接的”,而是接入每一比特的业务真实。这立刻引发了一场计算带来的恐慌。
2. 困局:三个团队的泥潭与灵魂拷问
按照传统软件工程的排期,搭建这条“全量管道”远比想象中复杂。它牵涉到 3 个研发团队的协同:前后端团队负责管道铺设,AI 团队负责数据清洗与萃取,EverMemOS 团队负责存储入库。
从产品调研、接口设计、开发、联调、测试到上线,即便我们全力以赴,接好一个 App 的周期至少需要一周。
陈天桥先生(陈总)的一句话,直接刺破了这种线性思维的幻想:
“一周接一个?那我们要接到什么时候去?”
这不仅仅是时间问题,更是复杂度爆炸的问题。当我们深入调研这 86 个 App 时,发现前方是一个巨大的泥潭:
接口参差不齐: Zoom、Notion 这种大厂有完美的 API;但 Midjourney、Lovart 这类新兴 AIGC 工具几乎没有官方 API。
哲学定义的模糊: 比如 Cursor 和 GitHub,“代码”本身是业务的真相吗? 还是说开发者编写代码的 Activity(活动记录) 才是我们需要的记忆?这不仅是技术问题,更是认知问题。
工程挑战的交织: 数据增量同步策略、API 限流熔断、复杂的权限映射……
产品设计问题(怎么接)、工程问题(怎么稳)、策略问题(接什么) 这三者死死纠缠在一起。
如果按照传统大公司的做法,要建立一个兼容 100+ App 的集成平台(Integration Platform),通常需要配置一个 10-20 人的全职团队,日复一日地干着苦力活。
但作为一家 AI Native 公司,我们绝不能接受这种解法。 传统“堆人头”的集成方式不仅效率低下,更是对技术杠杆的某种羞辱。我们拒绝把创造性的工作降级为按部就班的体力活。
我们必须找到一条属于 AI Native 的捷径。
3. 破局:用 AI 重新定义“管道”
面对这种线性增长的死局,我们没有选择加班,而是选择让 AI 先上。我们决定利用 AI 把这个高复杂度的问题进行降维打击。我们没有让 AI 去写代码,而是先让它帮我们解耦。
第一步:认知压缩,打破“全接入”的迷思

我们将 86 个 App 的清单连同我们的困惑(比如代码算不算记忆)一起喂给了 AI。我们要求 AI 跳出“软件分类”的窠臼,基于 Tanka 的业务流 重新定义它们。
AI 帮我们构建了一个全新的决策空间,将混乱的 86 个对象压缩为 3 种原生命题,瞬间厘清了那个困扰我们的“业务真实”到底是什么:
📥 Ingest(收集): 只有真正的“叙事性/结论性数据”才需要进入管道。比如文档、聊天记录。这才是 Memory 的本体。
🤝 Assist(赋能): 代码工具(Cursor)不需要被“存起来”,它们更需要被 Tanka Memory “反向赋能”,作为上下文去辅助生成。
⚡ Act(行动): 那些没有 API 的 AIGC 工具(Midjourney),不应该去硬爬数据,而应该通过 Agent 去**“驱动”**它们。
这一步把“如何接入 86 个 App”这个巨大的工程难题,拆解成了 3 类完全不同的战术动作。
第二步:数据视角的冷酷去噪
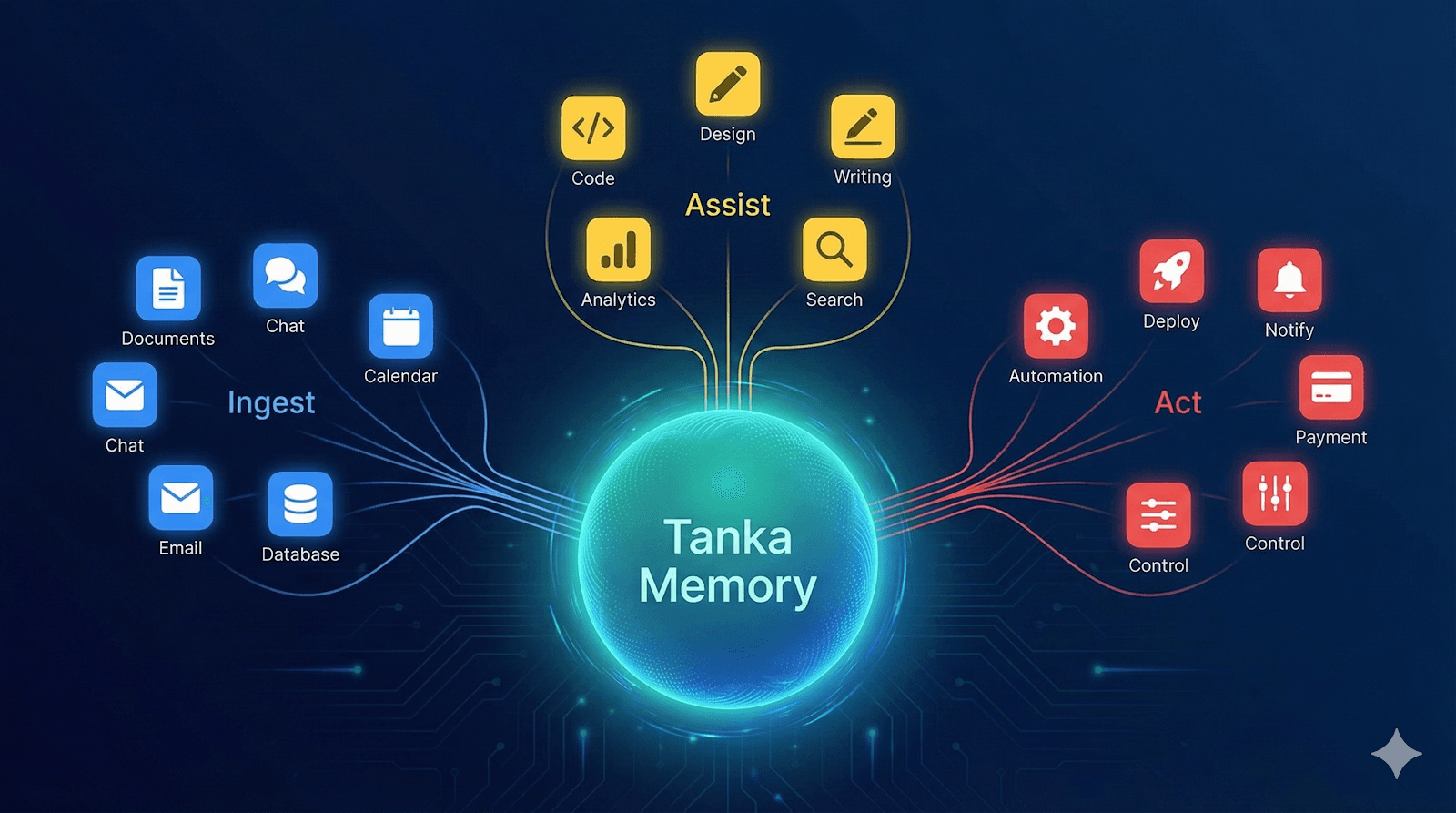
基于这个模型,AI 再次对清单进行扫描,给出的结论极大地减轻了管道的负载:
真正需要走复杂流程入库(Ingest)的,仅有 14 个。
适合做赋能(Assist)的:36 个。
适合 Agent 驱动(Act)的:27 个。
那个“一周接一个”的噩梦瞬间消散了。因为我们发现,**大部分软件根本不需要走那条最重的“集成开发链路”。**我们保住了“全量覆盖”的目标,但极大地缩减了工程半径。
第三步:从决策直接跳跃到协议
在 AI 帮我们理清了混乱的逻辑后,团队的精力从“写代码”回归到了“做判断”。 原本应该在“需求评审会”上扯皮的问题,变成了高效的**“人机对齐”**。一旦人类拍板,AI 直接将决策转化为了工程协议:统一的数据清洗 Schema、Context 注入标准接口。
原本三个团队(前后端、AI、OS)之间复杂的协作墙,被这套统一的协议打通了。
4. 深水区实战:当 API 不存在时
AI 帮我们理清了战略层面的分类(Ingest/Assist/Act),但在工程落地的深水区,我们依然面临着最棘手的挑战:当“业务真实”被锁在封闭花园里,或者 API 根本不存在时,我们该怎么办?
为了数据的完整性,我们必须展示出“黑客”的一面。
1. 攻破“高墙”:X (Twitter) 与 LinkedIn 的灰色突围
对于 X (Twitter) 和 LinkedIn 这样的社交平台,官方 API 极其昂贵且限制重重(例如无法获取私信)。但对于 Tanka Memory 而言,一条包含商务机密的 DM(私信)和一封邮件具有同等的价值。我们不能因为 API 的傲慢就放弃这部分记忆。
为了获取这份“业务真实”,我们采用了更激进的技术手段。
我们绕过了受限的官方接口,利用 Headless Browser (如 Puppeteer/Playwright) 技术模拟用户行为。
在合规的前提下,我们建立了一套“视觉层的管道”,像人类一样去“看”和“保存”动态与私信。数据主权。在 AI Native 时代,如果平台不给你梯子,你就得自己造飞机。
2. Midjourney 的“反向捕获”
在我们的分类中,Midjourney 属于 "Act"(驱动类)——我们要通过 Agent 去驱动它画图。 但问题来了:画出来的图也是公司的重要资产(Asset),如果不存下来,它们就会淹没在 Discord 的消息流里。
Midjourney 没有官方 API,怎么做“记忆回流”? 我们实施了一套“反向捕获”策略:我们部署了一个 Discord Bot 作为“潜伏者”,实时监听 Midjourney 的回调。一旦图片生成,Bot 立即拦截图片流,自动转存 S3 存储桶,并提取 Prompt 作为元数据打标入库。
5. 方法论:重构研发——从“线性接力”到“认知压缩”
跳出 Tanka Link 这个具体项目,让我们来看看 AI 时代的产品研发到底发生了什么本质变化。
在 Tanka,我们将这种变化总结为一套全新的工作流。它不再是传统大厂那种“需求→文档→开发”的线性接力,而是一个**「压缩认知 → 人类决策 → 立即执行」**的高频闭环。
您可以将其拆解为 6 个连续但高度压缩的阶段。这不仅是我们的一天,也是未来软件工程的标准时间线:
现实复杂输入 ↓ AI 认知压缩 ↓ 结构化决策空间 ↓ 人类关键取舍 ↓ 工程可执行方案 ↓ 当天进入研发
Step 1:人类定义“问题边界”,而非“解决方案”
这是启动键。人类依然不可替代,但职责变了。我们不再急着给出“怎么做”,而是专注于“要什么”和“怕什么”:
明确目标: “我们要把内容数据接入 Memory,但绝不触碰用户行为数据。”
明确约束: 合规底线在哪里?组织级权限怎么管?
明确标准: 输出必须能指导工程落地,不能是一份漂亮的废话分析。
👉 这一阶段,人类只做一件事:把问题说清楚,不急着给答案。
Step 2:AI 完成第一次「认知压缩」
当人类定义好边界,AI 开始承担最繁重的“阅读理解”工作。 面对 86 行混乱的软件清单,AI 自动完成了去噪、归类与抽象。它输出的不是单纯的建议,而是一个被压缩过的世界模型:
从零散的“86 个工具” → 变成有序的“3 类动作模型”。
Step 3:AI 构建“决策空间”,而非“直接结论”
这是最容易被误用的一步,但也是 AI 最强大的地方。 AI 并没有武断地说“你应该这样做”,而是帮我们构建了一个可供讨论的决策空间:
它列出了 Ingest / Assist / Act 三种路径;
它将每个工具放入候选位置,并附带了理由假设。 到这一步,人类不再面对混乱的噪音,而是在面对清晰的选项。
Step 4:人类进行「不可外包的取舍」
这是 AI 永远无法替代的“人类时刻”。 我们做的工作不是去修补 AI 的文案,而是反复拷问灵魂:
“如果今天只能做一半,砍哪一半?”
“哪些数据不接,反而是对用户的负责?”
“哪些能力不上,Tanka Link 就失去了灵魂?”
这里发生的不再是计算,而是责任、判断与对长期后果的承担。
👉 这才是人类在 AI 时代的真正价值点。
Step 5:AI 将“取舍”翻译成“工程语言”
一旦人类拍板,AI 再次进入高效执行模式。 它迅速将战略层面的“取舍”,扩展为工程层面的“结构”:接入范围、最小字段集、隔离假设、里程碑拆解。 这一步的本质是:把**“战略判断”无损翻译成“可执行代码”**。
Step 6:工程团队当日进入执行
当这一步开始时,已经没有关于“要不要做”的扯皮了。 工程团队拿到的直接是接口定义、事件流拆解和 Schema 设计。 AI 在这一天结束前完成了它的使命,世界平滑地交还给工程。
结语:AI Native 的本质
这套流程为什么是革命性的?
❌ 旧模式(线性低效): 人类必须从 0 想清楚到 1 → 痛苦地写文档 → 开会试图让别人理解 → 信息在传递中衰减。
✅ 新模式(液态高效): AI 瞬间把 0 → 0.6 的认知压缩完成 → 人类只负责 0.6 → 1 的关键判断 → 立即进入执行。
在 Tanka,我们不堆人,因为我们不需要人去处理那前 60% 的信息噪音。AI 在前,处理复杂;人类在后,把守关口。
这就是我们作为一家 AI Native 公司,拒绝按部就班、拒绝平庸效率的底气。
1. 从一张表格开始的“绝望计算”
故事的起点是一份被丢进 Slack 群的《公司付费软件统计表》。Notion, Slack, Zoom, Linear, Figma, Midjourney, Cursor... 统计显示,我们正在为 86 个不同的 SaaS 工具付费。
在 Tanka 的愿景里,我们需要通过 Tanka Link(这是我们连接外部世界的全量数据触手) 建立一条全量管道(Data Piping),把这些散落在各个孤岛中的数据接入 Tanka Memory。
一开始,研发团队的反应是线性的:“既然有 86 个,那我们就列个优先级,调研一批,排期一批,一个一个接。”
但紧接着,内部讨论推翻了这个逻辑。对于 Memory(记忆)而言,它不是一个“做减法”的选择题,而是一个“全量”的命题。因为你永远不知道哪一比特的碎片信息,会在未来成为 AI 决策的关键上下文。
所以,我们的目标不是“选几个好接的”,而是接入每一比特的业务真实。这立刻引发了一场计算带来的恐慌。
2. 困局:三个团队的泥潭与灵魂拷问
按照传统软件工程的排期,搭建这条“全量管道”远比想象中复杂。它牵涉到 3 个研发团队的协同:前后端团队负责管道铺设,AI 团队负责数据清洗与萃取,EverMemOS 团队负责存储入库。
从产品调研、接口设计、开发、联调、测试到上线,即便我们全力以赴,接好一个 App 的周期至少需要一周。
陈天桥先生(陈总)的一句话,直接刺破了这种线性思维的幻想:
“一周接一个?那我们要接到什么时候去?”
这不仅仅是时间问题,更是复杂度爆炸的问题。当我们深入调研这 86 个 App 时,发现前方是一个巨大的泥潭:
接口参差不齐: Zoom、Notion 这种大厂有完美的 API;但 Midjourney、Lovart 这类新兴 AIGC 工具几乎没有官方 API。
哲学定义的模糊: 比如 Cursor 和 GitHub,“代码”本身是业务的真相吗? 还是说开发者编写代码的 Activity(活动记录) 才是我们需要的记忆?这不仅是技术问题,更是认知问题。
工程挑战的交织: 数据增量同步策略、API 限流熔断、复杂的权限映射……
产品设计问题(怎么接)、工程问题(怎么稳)、策略问题(接什么) 这三者死死纠缠在一起。
如果按照传统大公司的做法,要建立一个兼容 100+ App 的集成平台(Integration Platform),通常需要配置一个 10-20 人的全职团队,日复一日地干着苦力活。
但作为一家 AI Native 公司,我们绝不能接受这种解法。 传统“堆人头”的集成方式不仅效率低下,更是对技术杠杆的某种羞辱。我们拒绝把创造性的工作降级为按部就班的体力活。
我们必须找到一条属于 AI Native 的捷径。
3. 破局:用 AI 重新定义“管道”
面对这种线性增长的死局,我们没有选择加班,而是选择让 AI 先上。我们决定利用 AI 把这个高复杂度的问题进行降维打击。我们没有让 AI 去写代码,而是先让它帮我们解耦。
第一步:认知压缩,打破“全接入”的迷思
我们将 86 个 App 的清单连同我们的困惑(比如代码算不算记忆)一起喂给了 AI。我们要求 AI 跳出“软件分类”的窠臼,基于 Tanka 的业务流 重新定义它们。
AI 帮我们构建了一个全新的决策空间,将混乱的 86 个对象压缩为 3 种原生命题,瞬间厘清了那个困扰我们的“业务真实”到底是什么:
📥 Ingest(收集): 只有真正的“叙事性/结论性数据”才需要进入管道。比如文档、聊天记录。这才是 Memory 的本体。
🤝 Assist(赋能): 代码工具(Cursor)不需要被“存起来”,它们更需要被 Tanka Memory “反向赋能”,作为上下文去辅助生成。
⚡ Act(行动): 那些没有 API 的 AIGC 工具(Midjourney),不应该去硬爬数据,而应该通过 Agent 去**“驱动”**它们。
这一步把“如何接入 86 个 App”这个巨大的工程难题,拆解成了 3 类完全不同的战术动作。
第二步:数据视角的冷酷去噪
基于这个模型,AI 再次对清单进行扫描,给出的结论极大地减轻了管道的负载:
真正需要走复杂流程入库(Ingest)的,仅有 14 个。
适合做赋能(Assist)的:36 个。
适合 Agent 驱动(Act)的:27 个。
那个“一周接一个”的噩梦瞬间消散了。因为我们发现,**大部分软件根本不需要走那条最重的“集成开发链路”。**我们保住了“全量覆盖”的目标,但极大地缩减了工程半径。
第三步:从决策直接跳跃到协议
在 AI 帮我们理清了混乱的逻辑后,团队的精力从“写代码”回归到了“做判断”。 原本应该在“需求评审会”上扯皮的问题,变成了高效的**“人机对齐”**。一旦人类拍板,AI 直接将决策转化为了工程协议:统一的数据清洗 Schema、Context 注入标准接口。
原本三个团队(前后端、AI、OS)之间复杂的协作墙,被这套统一的协议打通了。
4. 深水区实战:当 API 不存在时
AI 帮我们理清了战略层面的分类(Ingest/Assist/Act),但在工程落地的深水区,我们依然面临着最棘手的挑战:当“业务真实”被锁在封闭花园里,或者 API 根本不存在时,我们该怎么办?
为了数据的完整性,我们必须展示出“黑客”的一面。
1. 攻破“高墙”:X (Twitter) 与 LinkedIn 的灰色突围
对于 X (Twitter) 和 LinkedIn 这样的社交平台,官方 API 极其昂贵且限制重重(例如无法获取私信)。但对于 Tanka Memory 而言,一条包含商务机密的 DM(私信)和一封邮件具有同等的价值。我们不能因为 API 的傲慢就放弃这部分记忆。
为了获取这份“业务真实”,我们采用了更激进的技术手段。
我们绕过了受限的官方接口,利用 Headless Browser (如 Puppeteer/Playwright) 技术模拟用户行为。
在合规的前提下,我们建立了一套“视觉层的管道”,像人类一样去“看”和“保存”动态与私信。数据主权。在 AI Native 时代,如果平台不给你梯子,你就得自己造飞机。
2. Midjourney 的“反向捕获”
在我们的分类中,Midjourney 属于 "Act"(驱动类)——我们要通过 Agent 去驱动它画图。 但问题来了:画出来的图也是公司的重要资产(Asset),如果不存下来,它们就会淹没在 Discord 的消息流里。
Midjourney 没有官方 API,怎么做“记忆回流”? 我们实施了一套“反向捕获”策略:我们部署了一个 Discord Bot 作为“潜伏者”,实时监听 Midjourney 的回调。一旦图片生成,Bot 立即拦截图片流,自动转存 S3 存储桶,并提取 Prompt 作为元数据打标入库。
5. 方法论:重构研发——从“线性接力”到“认知压缩”
跳出 Tanka Link 这个具体项目,让我们来看看 AI 时代的产品研发到底发生了什么本质变化。
在 Tanka,我们将这种变化总结为一套全新的工作流。它不再是传统大厂那种“需求→文档→开发”的线性接力,而是一个**「压缩认知 → 人类决策 → 立即执行」**的高频闭环。
您可以将其拆解为 6 个连续但高度压缩的阶段。这不仅是我们的一天,也是未来软件工程的标准时间线:
现实复杂输入 ↓ AI 认知压缩 ↓ 结构化决策空间 ↓ 人类关键取舍 ↓ 工程可执行方案 ↓ 当天进入研发
Step 1:人类定义“问题边界”,而非“解决方案”
这是启动键。人类依然不可替代,但职责变了。我们不再急着给出“怎么做”,而是专注于“要什么”和“怕什么”:
明确目标: “我们要把内容数据接入 Memory,但绝不触碰用户行为数据。”
明确约束: 合规底线在哪里?组织级权限怎么管?
明确标准: 输出必须能指导工程落地,不能是一份漂亮的废话分析。
👉 这一阶段,人类只做一件事:把问题说清楚,不急着给答案。
Step 2:AI 完成第一次「认知压缩」
当人类定义好边界,AI 开始承担最繁重的“阅读理解”工作。 面对 86 行混乱的软件清单,AI 自动完成了去噪、归类与抽象。它输出的不是单纯的建议,而是一个被压缩过的世界模型:
从零散的“86 个工具” → 变成有序的“3 类动作模型”。
Step 3:AI 构建“决策空间”,而非“直接结论”
这是最容易被误用的一步,但也是 AI 最强大的地方。 AI 并没有武断地说“你应该这样做”,而是帮我们构建了一个可供讨论的决策空间:
它列出了 Ingest / Assist / Act 三种路径;
它将每个工具放入候选位置,并附带了理由假设。 到这一步,人类不再面对混乱的噪音,而是在面对清晰的选项。
Step 4:人类进行「不可外包的取舍」
这是 AI 永远无法替代的“人类时刻”。 我们做的工作不是去修补 AI 的文案,而是反复拷问灵魂:
“如果今天只能做一半,砍哪一半?”
“哪些数据不接,反而是对用户的负责?”
“哪些能力不上,Tanka Link 就失去了灵魂?”
这里发生的不再是计算,而是责任、判断与对长期后果的承担。
👉 这才是人类在 AI 时代的真正价值点。
Step 5:AI 将“取舍”翻译成“工程语言”
一旦人类拍板,AI 再次进入高效执行模式。 它迅速将战略层面的“取舍”,扩展为工程层面的“结构”:接入范围、最小字段集、隔离假设、里程碑拆解。 这一步的本质是:把**“战略判断”无损翻译成“可执行代码”**。
Step 6:工程团队当日进入执行
当这一步开始时,已经没有关于“要不要做”的扯皮了。 工程团队拿到的直接是接口定义、事件流拆解和 Schema 设计。 AI 在这一天结束前完成了它的使命,世界平滑地交还给工程。
结语:AI Native 的本质
这套流程为什么是革命性的?
❌ 旧模式(线性低效): 人类必须从 0 想清楚到 1 → 痛苦地写文档 → 开会试图让别人理解 → 信息在传递中衰减。
✅ 新模式(液态高效): AI 瞬间把 0 → 0.6 的认知压缩完成 → 人类只负责 0.6 → 1 的关键判断 → 立即进入执行。
在 Tanka,我们不堆人,因为我们不需要人去处理那前 60% 的信息噪音。AI 在前,处理复杂;人类在后,把守关口。
这就是我们作为一家 AI Native 公司,拒绝按部就班、拒绝平庸效率的底气。
1. 从一张表格开始的“绝望计算”
故事的起点是一份被丢进 Slack 群的《公司付费软件统计表》。Notion, Slack, Zoom, Linear, Figma, Midjourney, Cursor... 统计显示,我们正在为 86 个不同的 SaaS 工具付费。
在 Tanka 的愿景里,我们需要通过 Tanka Link(这是我们连接外部世界的全量数据触手) 建立一条全量管道(Data Piping),把这些散落在各个孤岛中的数据接入 Tanka Memory。
一开始,研发团队的反应是线性的:“既然有 86 个,那我们就列个优先级,调研一批,排期一批,一个一个接。”
但紧接着,内部讨论推翻了这个逻辑。对于 Memory(记忆)而言,它不是一个“做减法”的选择题,而是一个“全量”的命题。因为你永远不知道哪一比特的碎片信息,会在未来成为 AI 决策的关键上下文。
所以,我们的目标不是“选几个好接的”,而是接入每一比特的业务真实。这立刻引发了一场计算带来的恐慌。
2. 困局:三个团队的泥潭与灵魂拷问
按照传统软件工程的排期,搭建这条“全量管道”远比想象中复杂。它牵涉到 3 个研发团队的协同:前后端团队负责管道铺设,AI 团队负责数据清洗与萃取,EverMemOS 团队负责存储入库。
从产品调研、接口设计、开发、联调、测试到上线,即便我们全力以赴,接好一个 App 的周期至少需要一周。
陈天桥先生(陈总)的一句话,直接刺破了这种线性思维的幻想:
“一周接一个?那我们要接到什么时候去?”
这不仅仅是时间问题,更是复杂度爆炸的问题。当我们深入调研这 86 个 App 时,发现前方是一个巨大的泥潭:
接口参差不齐: Zoom、Notion 这种大厂有完美的 API;但 Midjourney、Lovart 这类新兴 AIGC 工具几乎没有官方 API。
哲学定义的模糊: 比如 Cursor 和 GitHub,“代码”本身是业务的真相吗? 还是说开发者编写代码的 Activity(活动记录) 才是我们需要的记忆?这不仅是技术问题,更是认知问题。
工程挑战的交织: 数据增量同步策略、API 限流熔断、复杂的权限映射……
产品设计问题(怎么接)、工程问题(怎么稳)、策略问题(接什么) 这三者死死纠缠在一起。
如果按照传统大公司的做法,要建立一个兼容 100+ App 的集成平台(Integration Platform),通常需要配置一个 10-20 人的全职团队,日复一日地干着苦力活。
但作为一家 AI Native 公司,我们绝不能接受这种解法。 传统“堆人头”的集成方式不仅效率低下,更是对技术杠杆的某种羞辱。我们拒绝把创造性的工作降级为按部就班的体力活。
我们必须找到一条属于 AI Native 的捷径。
3. 破局:用 AI 重新定义“管道”
面对这种线性增长的死局,我们没有选择加班,而是选择让 AI 先上。我们决定利用 AI 把这个高复杂度的问题进行降维打击。我们没有让 AI 去写代码,而是先让它帮我们解耦。
第一步:认知压缩,打破“全接入”的迷思
我们将 86 个 App 的清单连同我们的困惑(比如代码算不算记忆)一起喂给了 AI。我们要求 AI 跳出“软件分类”的窠臼,基于 Tanka 的业务流 重新定义它们。
AI 帮我们构建了一个全新的决策空间,将混乱的 86 个对象压缩为 3 种原生命题,瞬间厘清了那个困扰我们的“业务真实”到底是什么:
📥 Ingest(收集): 只有真正的“叙事性/结论性数据”才需要进入管道。比如文档、聊天记录。这才是 Memory 的本体。
🤝 Assist(赋能): 代码工具(Cursor)不需要被“存起来”,它们更需要被 Tanka Memory “反向赋能”,作为上下文去辅助生成。
⚡ Act(行动): 那些没有 API 的 AIGC 工具(Midjourney),不应该去硬爬数据,而应该通过 Agent 去**“驱动”**它们。
这一步把“如何接入 86 个 App”这个巨大的工程难题,拆解成了 3 类完全不同的战术动作。
第二步:数据视角的冷酷去噪
基于这个模型,AI 再次对清单进行扫描,给出的结论极大地减轻了管道的负载:
真正需要走复杂流程入库(Ingest)的,仅有 14 个。
适合做赋能(Assist)的:36 个。
适合 Agent 驱动(Act)的:27 个。
那个“一周接一个”的噩梦瞬间消散了。因为我们发现,**大部分软件根本不需要走那条最重的“集成开发链路”。**我们保住了“全量覆盖”的目标,但极大地缩减了工程半径。
第三步:从决策直接跳跃到协议
在 AI 帮我们理清了混乱的逻辑后,团队的精力从“写代码”回归到了“做判断”。 原本应该在“需求评审会”上扯皮的问题,变成了高效的**“人机对齐”**。一旦人类拍板,AI 直接将决策转化为了工程协议:统一的数据清洗 Schema、Context 注入标准接口。
原本三个团队(前后端、AI、OS)之间复杂的协作墙,被这套统一的协议打通了。
4. 深水区实战:当 API 不存在时
AI 帮我们理清了战略层面的分类(Ingest/Assist/Act),但在工程落地的深水区,我们依然面临着最棘手的挑战:当“业务真实”被锁在封闭花园里,或者 API 根本不存在时,我们该怎么办?
为了数据的完整性,我们必须展示出“黑客”的一面。
1. 攻破“高墙”:X (Twitter) 与 LinkedIn 的灰色突围
对于 X (Twitter) 和 LinkedIn 这样的社交平台,官方 API 极其昂贵且限制重重(例如无法获取私信)。但对于 Tanka Memory 而言,一条包含商务机密的 DM(私信)和一封邮件具有同等的价值。我们不能因为 API 的傲慢就放弃这部分记忆。
为了获取这份“业务真实”,我们采用了更激进的技术手段。
我们绕过了受限的官方接口,利用 Headless Browser (如 Puppeteer/Playwright) 技术模拟用户行为。
在合规的前提下,我们建立了一套“视觉层的管道”,像人类一样去“看”和“保存”动态与私信。数据主权。在 AI Native 时代,如果平台不给你梯子,你就得自己造飞机。
2. Midjourney 的“反向捕获”
在我们的分类中,Midjourney 属于 "Act"(驱动类)——我们要通过 Agent 去驱动它画图。 但问题来了:画出来的图也是公司的重要资产(Asset),如果不存下来,它们就会淹没在 Discord 的消息流里。
Midjourney 没有官方 API,怎么做“记忆回流”? 我们实施了一套“反向捕获”策略:我们部署了一个 Discord Bot 作为“潜伏者”,实时监听 Midjourney 的回调。一旦图片生成,Bot 立即拦截图片流,自动转存 S3 存储桶,并提取 Prompt 作为元数据打标入库。
5. 方法论:重构研发——从“线性接力”到“认知压缩”
跳出 Tanka Link 这个具体项目,让我们来看看 AI 时代的产品研发到底发生了什么本质变化。
在 Tanka,我们将这种变化总结为一套全新的工作流。它不再是传统大厂那种“需求→文档→开发”的线性接力,而是一个**「压缩认知 → 人类决策 → 立即执行」**的高频闭环。
您可以将其拆解为 6 个连续但高度压缩的阶段。这不仅是我们的一天,也是未来软件工程的标准时间线:
现实复杂输入 ↓ AI 认知压缩 ↓ 结构化决策空间 ↓ 人类关键取舍 ↓ 工程可执行方案 ↓ 当天进入研发
Step 1:人类定义“问题边界”,而非“解决方案”
这是启动键。人类依然不可替代,但职责变了。我们不再急着给出“怎么做”,而是专注于“要什么”和“怕什么”:
明确目标: “我们要把内容数据接入 Memory,但绝不触碰用户行为数据。”
明确约束: 合规底线在哪里?组织级权限怎么管?
明确标准: 输出必须能指导工程落地,不能是一份漂亮的废话分析。
👉 这一阶段,人类只做一件事:把问题说清楚,不急着给答案。
Step 2:AI 完成第一次「认知压缩」
当人类定义好边界,AI 开始承担最繁重的“阅读理解”工作。 面对 86 行混乱的软件清单,AI 自动完成了去噪、归类与抽象。它输出的不是单纯的建议,而是一个被压缩过的世界模型:
从零散的“86 个工具” → 变成有序的“3 类动作模型”。
Step 3:AI 构建“决策空间”,而非“直接结论”
这是最容易被误用的一步,但也是 AI 最强大的地方。 AI 并没有武断地说“你应该这样做”,而是帮我们构建了一个可供讨论的决策空间:
它列出了 Ingest / Assist / Act 三种路径;
它将每个工具放入候选位置,并附带了理由假设。 到这一步,人类不再面对混乱的噪音,而是在面对清晰的选项。
Step 4:人类进行「不可外包的取舍」
这是 AI 永远无法替代的“人类时刻”。 我们做的工作不是去修补 AI 的文案,而是反复拷问灵魂:
“如果今天只能做一半,砍哪一半?”
“哪些数据不接,反而是对用户的负责?”
“哪些能力不上,Tanka Link 就失去了灵魂?”
这里发生的不再是计算,而是责任、判断与对长期后果的承担。
👉 这才是人类在 AI 时代的真正价值点。
Step 5:AI 将“取舍”翻译成“工程语言”
一旦人类拍板,AI 再次进入高效执行模式。 它迅速将战略层面的“取舍”,扩展为工程层面的“结构”:接入范围、最小字段集、隔离假设、里程碑拆解。 这一步的本质是:把**“战略判断”无损翻译成“可执行代码”**。
Step 6:工程团队当日进入执行
当这一步开始时,已经没有关于“要不要做”的扯皮了。 工程团队拿到的直接是接口定义、事件流拆解和 Schema 设计。 AI 在这一天结束前完成了它的使命,世界平滑地交还给工程。
结语:AI Native 的本质
这套流程为什么是革命性的?
❌ 旧模式(线性低效): 人类必须从 0 想清楚到 1 → 痛苦地写文档 → 开会试图让别人理解 → 信息在传递中衰减。
✅ 新模式(液态高效): AI 瞬间把 0 → 0.6 的认知压缩完成 → 人类只负责 0.6 → 1 的关键判断 → 立即进入执行。
在 Tanka,我们不堆人,因为我们不需要人去处理那前 60% 的信息噪音。AI 在前,处理复杂;人类在后,把守关口。
这就是我们作为一家 AI Native 公司,拒绝按部就班、拒绝平庸效率的底气。
Written by Jack Wang
现任 Tanka(AI 原生企业运营基座)副总裁
负责领导面向真实工作场景的先进长期记忆系统研发,致力于将日常对话、文档和决策转化为持久的组织智能。结合计算机科学与生物学的双重背景,他探索出一条受 AGI 启发的路径:将强大的推理模型(类比“前额叶”)与稳健的记忆架构(类比“海马体”)相结合,旨在构建不仅仅是被动响应,而是能持续学习、保留语境并实现生产力复利增长的 AI 系统。
